SISTEMAS DE MULTIPLES PROCESADORES
Desde su inicio, la industria de las computadoras se ha orientado fundamentalmente a buscar sin
pausa un poder de cómputo cada vez mayor. La ENIAC podía realizar 300 operaciones por segundo
—es decir, era 1000 veces más rápida que cualquier calculadora anterior a ella— pero aún así
las personas no estaban satisfechas. Las máquinas actuales son millones de veces más rápidas que
la ENIAC y sigue existiendo una demanda de mayor potencia de cómputo. Los astrónomos están
tratando de entender el universo, los biólogos tratan de comprender las implicaciones del genoma
humano y los ingenieros aeronáuticos están interesados en construir aeronaves más seguras y eficientes,
y todos ellos requieren más ciclos de la CPU. No importa cuánto poder de cómputo haya
disponible, nunca será suficiente.

De antemano en los sistemas Pentium de alto rendimiento, el enfriador de la CPU es más grande que la misma CPU. Con todo,
para pasar de 1 MHz a 1 GHz se requirió sólo una ingeniería cada vez mejor del proceso de fabricacióndel chip; para pasar de 1 GHz a 1 THz se va a requerir una metodología radicalmente
distinta.
Una metodología para obtener una mayor velocidad es a través de las computadoras masivamente
en paralelo. Estas máquinas consisten en muchas CPUs, cada una de las cuales opera a una
velocidad “normal” (lo que eso signifique en cierto año específico), pero que en conjunto tienen
mucho más poder de cómputo que una sola CPU. Ahora hay sistemas con 1000 CPUs disponibles
comercialmente. Es probable que se construyan sistemas con 1 millón de CPUs en la siguiente década.
Aunque hay otras metodologías potenciales para obtener mayor velocidad, como las computadoras
biológicas, en este capítulo nos enfocaremos en los sistemas con varias CPUs convencionales.

A continuación tenemos el sistema de la figura 8-1(b), en el cual varios pares de CPU-memoria
se conectan a una interconexión de alta velocidad. A este tipo de sistema se le conoce como multicomputadora
con paso de mensajes. Cada memoria es local para una sola CPU y puede ser utilizada
sólo por esa CPU. Las CPUs se comunican enviando mensajes de varias palabras a través de la interconexión.
Con una buena interconexión, un mensaje corto se puede enviar en un tiempo de 10 a
50 μseg, pero aún es más largo que el tiempo de acceso a la memoria de la figura 8-1(a). No hay memoria
global compartida en este diseño. Las multicomputadoras (es decir, sistemas de paso de mensajes)
son mucho más fáciles de construir que los multiprocesadores (memoria compartida), pero son
más difíciles de programar. Por lo tanto, cada género tiene sus admiradores.
El tercer modelo, que se ilustra en la figura 8-1(c), conecta sistemas de cómputo completos a través
de una red de área amplia como Internet, para formar un sistema distribuido. Cada uno de estos
sistemas tiene su propia memoria, y los sistemas se comunican mediante el paso de mensajes. La
única diferencia real entre la figura 8-1(b) y la figura 8-1(c) es que en esta última se utilizan computadoras
completas, y los tiempos de los mensajes son comúnmente entre 10 y 100 mseg. Este largo
retraso obliga a que estos sistemas débilmente acoplados se utilicen de maneras distintas a los sistemas
fuertemente acoplados de la figura 8-1(b). Los tres tipos de sistemas difieren en sus retrasos
por una cantidad aproximada a los tres órdenes de magnitud. Ésa es la diferencia entre un día y tres
años.
MULTIPROCESADORES
Un multiprocesador con memoria compartida (o sólo multiprocesador, de aquí en adelante) es
un sistema de cómputo en el que dos o más CPUs comparten todo el acceso a una RAM común. Un
programa que se ejecuta en cualquiera de las CPUs ve un espacio normal de direcciones virtuales
(por lo general paginadas).

En su mayor parte, los sistemas operativos multiprocesadores son sólo sistemas operativos regulares.
Manejan las llamadas al sistema, administran la memoria, proveen un sistema de archivos
y administran los dispositivos de E/S. Sin embargo, hay ciertas áreas en las que tienen características
únicas. Estas áreas son la sincronización de procesos, la administración de recursos y la programación
de tareas. A continuación analizaremos con brevedad el hardware de los multiprocesadores
y después pasaremos a ver las cuestiones relacionadas con estos sistemas operativos.
Hardware de multiprocesador
Aunque todos los multiprocesadores tienen la propiedad de que cada CPU puede direccionar toda la
memoria, algunos tienen la característica adicional de que cada palabra de memoria se puede leer con
la misma velocidad que cualquier otra palabra de memoria. Estas máquinas se conocen como multiprocesadores
UMA (Uniform Memory Access, Acceso uniforme a la memoria). Por el contrario, los multiprocesadores
NUMA (Non-uniform Memory Access, Acceso no uniforme a la memoria) no tienen
esta propiedad.

Multiprocesadores UMA con arquitecturas basadas en bus
Los multiprocesadores más simples se basan en un solo bus, como se ilustra en la figura 8-2(a). Dos
o más CPUs y uno o más módulos de memoria utilizan el mismo bus para comunicarse. Cuando
una CPU desea leer una palabra de memoria, primero comprueba si el bus está ocupado. Si está
inactivo, la CPU coloca la dirección de la palabra que desea en el bus, declara unas cuantas señales
de control y espera hasta que la memoria coloque la palabra deseada en el bus.
Si el bus está ocupado cuando una CPU desea leer o escribir en la memoria, la CPU espera sólo
hasta que el bus esté inactivo. Aquí es donde se encuentra el problema con este diseño. Con dos
o tres CPUs, la contención por el bus será manejable; con 32 o 64 será imposible. El sistema estará
totalmente limitado por el ancho de banda del bus, y la mayoría de las CPUs estarán inactivas la
mayor parte del tiempo.
La solución a este problema es agregar una caché a cada CPU, como se ilustra en la figura
8.2(b). La caché puede estar dentro del chip de la CPU, a un lado de ésta, en el tablero del procesador
o puede ser alguna combinación de las tres opciones anteriores. Como esto permite satisfacer
muchas operaciones de lectura desde la caché local, habrá mucho menos tráfico en el bus y el sistema
podrá soportar más CPUs. En general, el uso de caché no se realiza por cada palabra individual, sino
por bloques de 32 o 64 bytes. Cuando se hace referencia a una palabra, se obtiene su bloque completo
(conocido como línea de caché) y se coloca en la caché de la CPU que está en contacto con ella.

Otra posibilidad es el diseño de la figura 8-2(c), donde cada CPU tiene no sólo una caché, sino
también una memoria privada local que utiliza mediante un bus dedicado (privado). Para utilizar esta
configuración de manera óptima, el compilador debe colocar todo el texto del programa, las cadenas,
constantes y demás datos de sólo lectura, las pilas y las variables locales en las memorias
privadas.
Multiprocesadores UMA que utilizan interruptores de barras cruzadas
Aun con la mejor caché, el uso de un solo bus limita el tamaño de un multiprocesador UMA a 16 o
32 CPUs, aproximadamente. Para lograr algo más se necesita un tipo distinto de interconexión. El
circuito más simple para conectar n CPUs a k memorias es el interruptor (conmutador) de barras
cruzadas, que se muestra en la figura 8-3. Los interruptores de barras cruzadas se han utilizado
por décadas en los puntos de intercambio de los conmutadores telefónicos para conectar un
grupo de líneas entrantes a un conjunto de líneas salientes de manera arbitraria.

Multiprocesadores NUMA
Al igual que sus parientes UMA, proveen un solo espacio de direcciones a través de todas
las CPUs, pero a diferencia de las máquinas UMA, el acceso a los módulos de memoria locales
es más rápido que el acceso a los remotos. Por ende, todos los programas UMA se ejecutarán sin
cambios en las máquinas NUMA, pero el rendimiento será peor que en una máquina UMA a la misma
velocidad de reloj.
Las máquinas NUMA poseen tres características clave que, en conjunto, las distinguen de otros
multiprocesadores:
1. Hay un solo espacio de direcciones visible para todas las CPUs.
2. El acceso a la memoria remota es mediante instrucciones LOAD y STORE.
3. El acceso a la memoria remota es más lento que el acceso a la memoria local.

Tipos de sistemas operativos multiprocesador
Cada CPU tiene su propio sistema operativo.
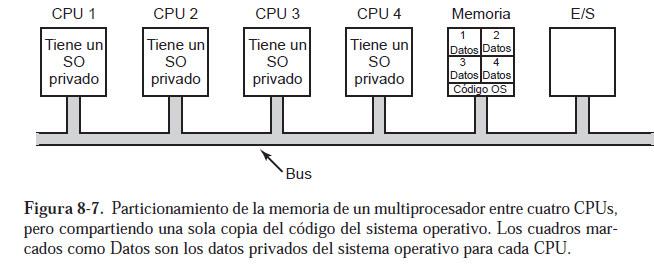
La manera más simple posible de organizar un sistema operativo multiprocesador es dividir estáticamente
la memoria y su propia copia privada del sistema operativo. En efecto, las n CPUs operan
entonces como n computadoras independientes. Una optimización obvia es permitir que todas las
CPUs compartan el código del sistema operativo y obtengan copias privadas sólo de las estructuras
de datos del sistema operativo, como se muestra en la figura 8-7.
Multiprocesadores maestro-esclavo
En la figura 8-8 se muestra un segundo modelo. Aquí, hay una copia del sistema operativo y sus tablas
presente en la CPU 1, y nada más ahí. Todas las llamadas al sistema se redirigen a la CPU 1
para procesarlas ahí. La CPU 1 también puede ejecutar proceso de usuario si tiene tiempo de sobra.
A este modelo se le conoce como maestro-esclavo, ya que la CPU 1 es el maestro y todas los demás
son los esclavos.

Multiprocesadores simétricos
Nuestro tercer modelo, el SMP (Multiprocesador simétrico), elimina esta asimetría. Hay una copia
del sistema operativo en memoria, pero cualquier CPU puede ejecutarlo. Cuando se hace una
llamada al sistema, la CPU en la que se hizo la llamada al sistema atrapa para el kernel y procesa
la llamada al sistema. El modelo SMP se ilustra en la figura 8-9.

Este modelo equilibra los procesos y la memoria en forma dinámica, ya que sólo hay un conjunto
de tablas del sistema operativo. También elimina el cuello de botella de la CPU, ya que no hay
maestro, pero introduce sus propios problemas. En especial, si dos o más CPUs están ejecutando
código del sistema operativo al mismo tiempo, se puede producir un desastre. Imagine que dos
CPUs seleccionan el mismo proceso para ejecutarlo, o que reclaman la misma página de memoria
libre. La solución más simple para estos problemas es asociar un mutex (es decir, bloqueo) con el
sistema operativo, convirtiendo a todo el sistema en una gran región crítica. Cuando una CPU desea
ejecutar código del sistema operativo, debe adquirir primero el mutex. Si el mutex está bloqueado,
sólo espera. De esta forma, cualquier CPU puede ejecutar el sistema operativo, pero sólo una a
la vez.
Sincronización de multiprocesadores
Para empezar, realmente se necesitan primitivas de sincronización apropiadas. Si un proceso en
una máquina uniprocesador (sólo una CPU) realiza una llamada al sistema que requiera acceder a
cierta tabla crítica del kernel, el código del kernel sólo tiene que deshabilitar las interrupciones antes
de tocar la tabla. Después puede hacer su trabajo, sabiendo que podrá terminar sin que ningún
otro proceso se entrometa y toque la tabla antes de que haya terminado. En un sistema multiprocesador,
deshabilitar las interrupciones sólo afecta a esa CPU, desshilitándola. Las demás CPUs se siguen
ejecutando y aún pueden tocar la tabla crítica. Como consecuencia, se debe utilizar un protocolo
de mutex apropiado, el cual debe ser respetado por todas las CPUs para garantizar que funcione la
exclusión mutua.
Ahora piense en lo que podría ocurrir en un multiprocesador. En la figura 8-10 podemos ver la
sincronización en el peor caso, en donde la palabra de memoria 1000, que se utiliza como bloqueo,
en un principio es 0. En el paso 1, la CPU 1 lee la palabra y obtiene un 0. En el paso 2, antes de que
la CPU 1 tenga la oportunidad de volver a escribir la palabra para que sea 1, la CPU 2 entra y también
lee la palabra como un 0. En el paso 3, la CPU 1 escribe un 1 en la palabra. En el paso 4, la
CPU 2 también escribe un 1 en la palabra. Ambas CPUs obtuvieron un 0 de la instrucción TSL, por
lo que ambas tienen ahora acceso a la región crítica y falla la exclusión mutua.

Para evitar este problema, la instrucción TSL debe primero bloquear el bus, para evitar que otras
CPUs lo utilicen; después debe realizar ambos accesos a la memoria, y luego desbloquear el bus.
Por lo general, para bloquear el bus se hace una petición del bus usando el protocolo de petición de
bus común, y después se declara (es decir, se establece a un 1 lógico) cierta línea de bus especial
hasta que se hayan completado ambos ciclos. Mientras que esté declarada esta línea especial, ninguna
otra CPU obtendrá acceso al bus. Esta instrucción puede implementarse sólo en un bus que
tenga las líneas necesarias y el protocolo (de hardware) para utilizarlas. Los buses modernos tienen
estas facilidades, pero en los primeros que no las tenían, no era posible implementar la instrucción
TSL en forma correcta. Ésta es la razón por la que se inventó el protocolo de Peterson: para sincronizar
por completo en el software (Peterson, 1981).
Planificación de multiprocesadores
Antes de analizar la forma en que se realiza la planificación en los multiprocesadores, es necesario
determinar qué es lo que se va a planificar. En los días de antaño, cuando todos los procesos tenían
un solo hilo, los procesos eran los que se planificaban; no había nada más que se pudiera planificar.
Todos los sistemas operativos modernos soportan procesos multihilo, lo cual complica aún más la
planificación.
Es importante saber si los hilos son de kernel o de usuario. Si la ejecución de hilos se lleva a
cabo mediante una biblioteca en espacio de usuario y el kernel no sabe nada acerca de los hilos, entonces
la planificación se lleva a cabo con base en cada proceso, como siempre. Si el kernel ni siquiera
sabe que los hilos existen, es muy difícil que pueda planificarlos.

Con los hilos del kernel sucede algo distinto. Aquí el kernel está al tanto de todos los hilos
y puede elegir y seleccionar de entre los hilos que pertenecen a un proceso. En estos sistemas, la
tendencia es que el kernel seleccione un hilo para ejecutarlo, y el proceso al que pertenece sólo
tiene un pequeño papel (o tal vez ninguno) en el algoritmo de selección de hilos. A continuación
hablaremos sobre la planificación de hilos, pero desde luego que, en un sistema con procesos con
un solo hilo, o con hilos implementados en espacio de usuario, son los procesos los que se programan.
Proceso contra hilo no es la única cuestión de planificación. En un uniprocesador, la planificación
es de una dimensión. La única pregunta que hay que responder (repetidas veces) es:
“¿Cuál hilo se debe ejecutar a continuación?”. En un multiprocesador, la planificación tiene dos
dimensiones: el planificador tiene que decidir qué hilo ejecutar y en cuál CPU lo va a ejecutar.
Esta dimensión adicional complica de manera considerable la planificación en los multiprocesadores.
Otro factor que complica las cosas es que, en ciertos sistemas, ninguno de los hilos está relacionado,
mientras que en otros se dividen en grupos donde todos pertenecen a la misma aplicación
y trabajan en conjunto. Un ejemplo del primer caso es un sistema de tiempo compartido, en
el que usuarios independientes inician procesos independientes. Los hilos de los distintos procesos
no están relacionados, y cada uno de ellos se puede planificar de manera independiente a los
demás.
Tiempo compartido
Vamos a analizar el caso de la programación de hilos independientes; más adelante consideraremos
cómo planificar hilos relacionados. El algoritmo de planificación más simple para lidiar con hilos
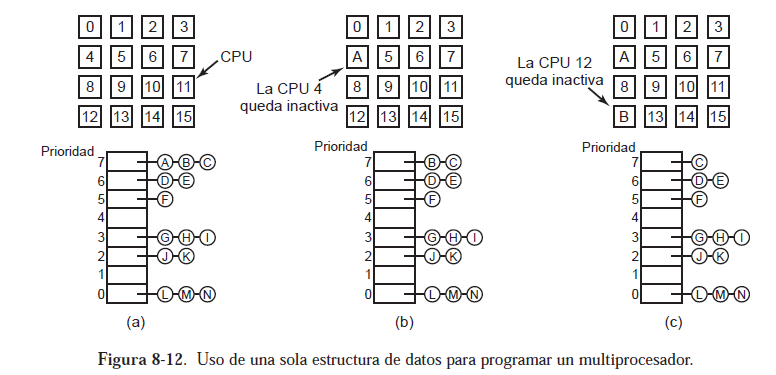
no relacionados es tener una sola estructura de datos a nivel de sistema para los hilos que estén listos,
que tal vez sea sólo una lista, pero es mucho más probable que sea un conjunto de listas para
los hilos con distintas prioridades, como se ilustra en la figura 8-12(a). Aquí, las 16 CPUs están ocupadas
en un momento dado, y hay un conjunto de 14 hilos por orden de prioridad, esperando ser
ejecutados. La primera CPU en terminar su trabajo actual (o en hacer que su hilo se bloquee) es la
CPU 4, que después bloquea las colas de programación y selecciona el hilo con mayor prioridad
(A), como se muestra en la figura 8-12(b). A continuación, la CPU 12 queda inactiva y selecciona
el hilo B, como se ilustra en la figura 8-12(c). Mientras que los hilos no estén relacionados de ninguna manera, es una opción razonable llevar a cabo la planificación de esta forma, y es muy simple de implementar con eficiencia
Espacio compartido
El otro método general para la planificación de multiprocesadores se puede utilizar cuando los hilos
están relacionados entre sí de alguna manera. Anteriormente mencionamos el ejemplo del programa
make paralelo como uno de los casos. También ocurre con frecuencia que un solo proceso tenga varios
hilos que trabajen en conjunto. Por ejemplo, si los hilos de un proceso se comunican con mucha
frecuencia, es conveniente hacer que se ejecuten al mismo tiempo. A la planificación de varios hilos
al mismo tiempo, esparcidos sobre varias CPUs, se le conoce como espacio compartido.
En cualquier instante, el conjunto de CPUs se divide de manera estática en cierto número de
particiones, cada una de las cuales ejecuta los hilos de un hilo. Por ejemplo, en la figura 8-13 hay
particiones con 4, 6, 8 y 12 CPUs, y hay 2 CPUs sin asignar. Con el tiempo cambiará el número y
el tamaño de las particiones, a medida que se creen nuevos hilos y cuando los anteriores terminen
de ejecutarse.

Planificación por pandilla
Es una consecuencia de la
co-planificación (Ousterhout, 1982). La planificación por pandilla consta de tres partes:
1. Los grupos de hilos relacionados se programan como una unidad, o pandilla.
2. Todos los miembros de una plantilla se ejecutan en forma simultánea, en distintas CPUs de
tiempo compartido.
3. Todos los miembros de la pandilla inician y terminan sus intervalos en conjunto.
En la figura 8-15 se muestra un ejemplo del funcionamiento de la planificación por pandilla.
Aquí tenemos un multiprocesador con seis CPUs que son utilizadas por cinco procesos (A a E), con
un total de 24 hilos listos para ejecutarse. Durante la ranura de tiempo 0, se programan los hilos A0
a A6 y se ejecutan. Durante la ranura de tiempo 1, se programan los hilos B0, B1, B2, C0, C1 y C2, y
se ejecutan. Durante la ranura de tiempo 2, se ejecutan los cinco hilos de D y E0. Los seis hilos restantes
que pertenecen al hilo E se ejecutan en la ranura de tiempo 3. Después se repite el ciclo, donde
la ranura 4 es igual a la ranura 0, y así en lo sucesivo.

Muy Bien, buena aportación!!!
ResponderBorrargracias ing. carito buenas noches :)
BorrarMuy buena explicación, graciass!!
ResponderBorrar